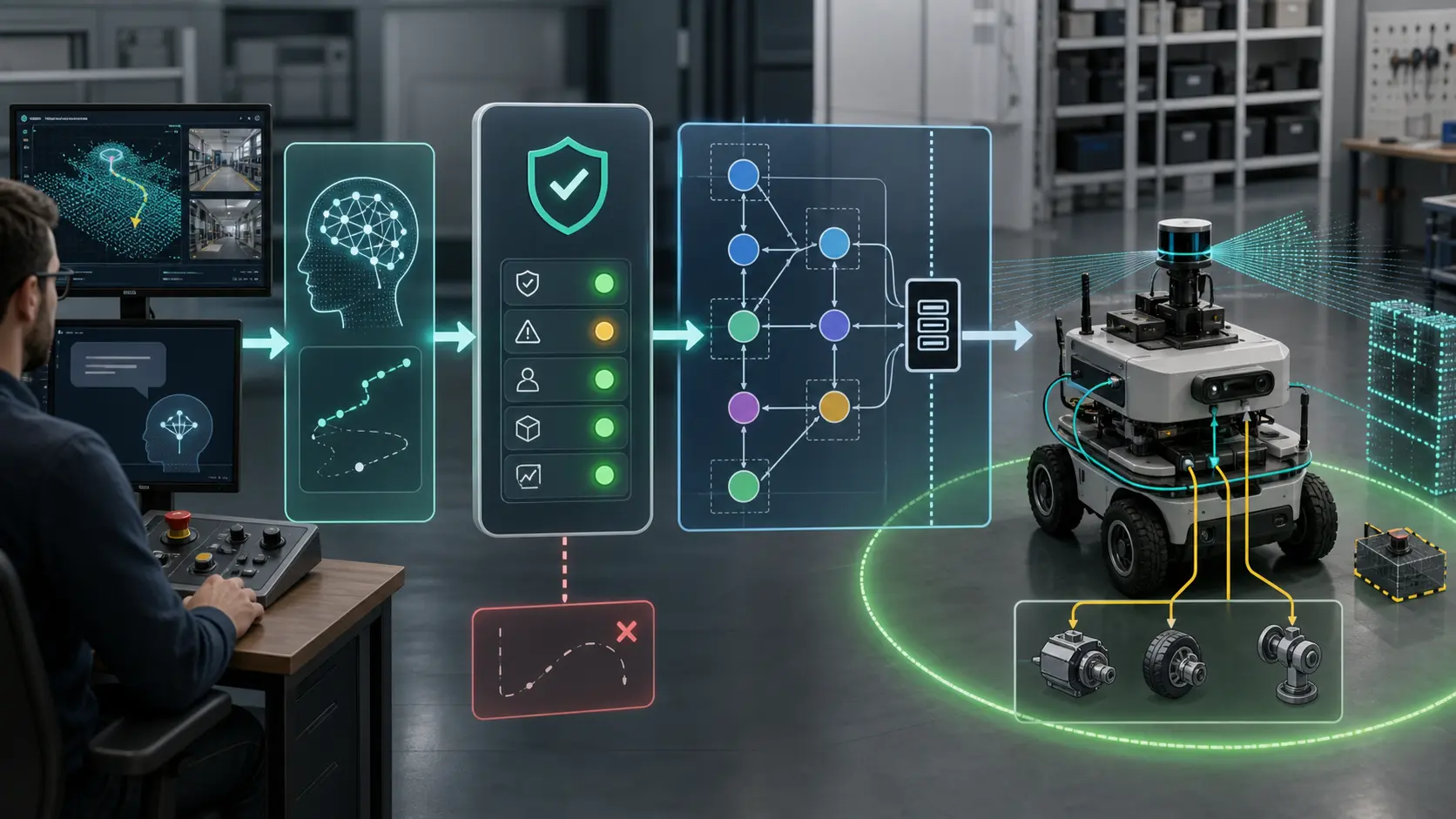
AI robot agents fail dangerously when their output is treated as a command.
They become useful when their output is treated as a proposal.
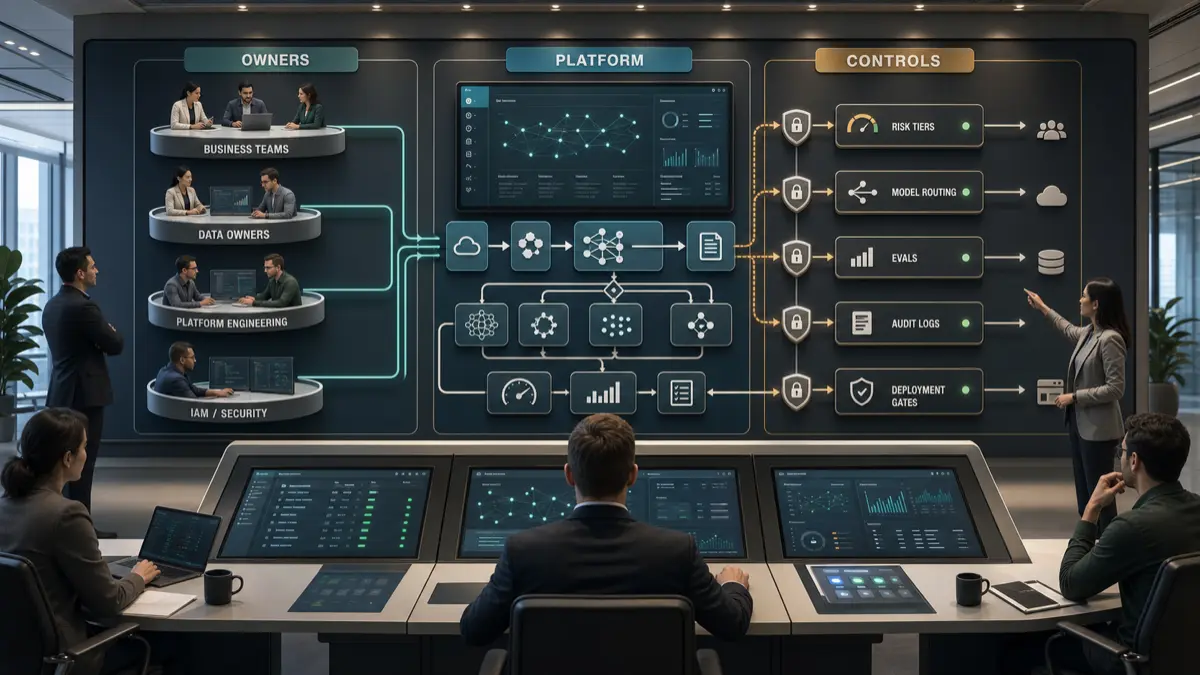
That distinction is the reason to build a command validation layer between the AI agent and the robot. The validator is the deterministic gate that decides whether an AI-generated request may become a ROS 2 action goal, a supervised skill, a maintenance workflow, or nothing at all.