
I wanted an AI system that could generate beautiful, production-ready newsletter HTML from a single prompt, while still being reliable enough for real workflows. Agentic workflows are designed for real world applications, enabling generative AI systems to automate repetitive tasks, reduce human effort, and increase operational speed. In this project, generative AI powers the agentic workflows that drive the system.
The constraint was clear: I already have a brand package (logo, colors, fonts, voice). The hard part is the agentic generation pipeline itself. The core components of the AI agent architecture—such as the planner, executor, and evaluator—are essential for enabling autonomous behavior and ensuring the agent can function effectively in practical scenarios.
This post explains how I designed the agent, why I split responsibilities across multiple LLM calls (strategist, stylist, copywriter, etc.), what failed early on, and what finally worked.
1) Why one giant prompt was not enough
At first, I tried a single “do-everything” prompt: strategy + layout + copy + image choices + email-safe HTML.
It worked sometimes, but I kept seeing:
repetitive layouts
unreadable contrast in some sections
weak adaptation to complex prompts (ex: “7 sections with pros/cons + many images”)
fragile HTML structure for email clients
So I moved to a multi-agent pipeline where each step has one job and strict output contracts. In this setup, sequential workflows allow AI agents to adapt, learn, and make decisions dynamically within a given context to complete tasks more effectively. Agentic workflows enable the system to handle complex requirements by letting agents collaborate and adjust their actions, which is a significant improvement over rigid, rule-based automation.
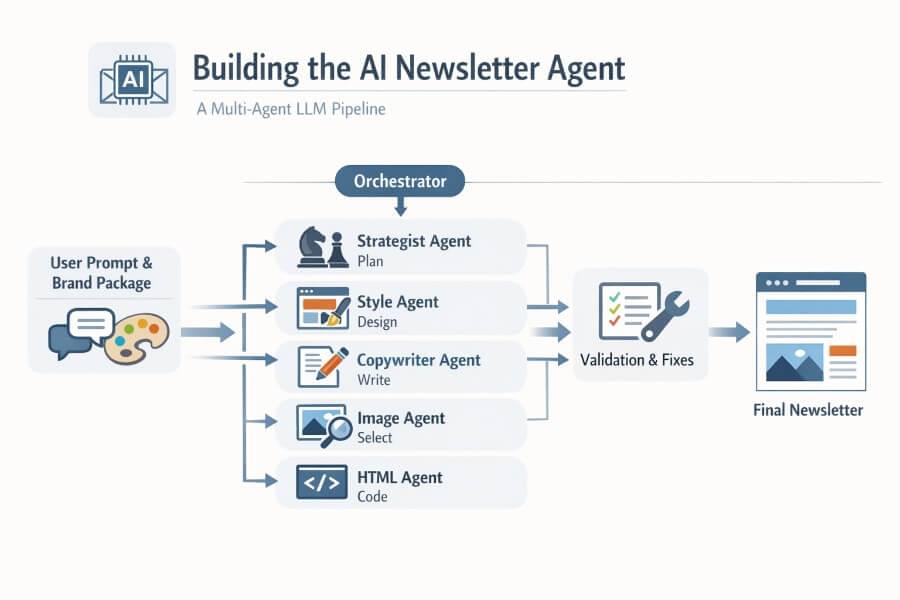
2) The final architecture of multi agent systems (high level)
The orchestrator runs specialized agents in sequence, with lightweight validation between steps. Each agent is responsible for specific tasks within the workflow, ensuring efficient task execution and effective tool use throughout the process.

The AI agent architecture is modular, comprising core components such as the brain (LLM), memory, and tools. This modularity allows different components to work cohesively and efficiently. Tool use is integrated at various stages to support the completion of complex tasks, such as image placement and HTML composition. Action execution translates the agents’ plans into tangible actions, like calling external APIs or generating markup, enabling the system to act independently to achieve its goals.
3) Agent responsibilities and LLM calls
In practice, a single generation usually takes 5 to 7 LLM calls:
standard flow: 5 calls
with QA repair loop: +1 or +2 calls
1) Strategist Agent
Goal: Convert user prompt into an actionable editorial plan. The Strategist Agent commits to specific intentions and actions based on the user’s objectives, mirroring the rational decision-making process found in BDI architecture, where agents act according to their beliefs, desires, and intentions.
Input: raw prompt, brand voice metadata.
Output (JSON):
audience
objective
section list (explicit count)
CTA strategy
content depth per section
Why this matters: it forces the system to respect user intent like “7 parts” or “include benefits and drawbacks”.
2) Style Director Agent
Goal: Design the visual composition, not the words.
Input: strategy output + brand tokens.
Output (JSON):
layout blueprint (hero, split blocks, grid blocks, feature rows, closing CTA)
alternation rules (left-image/right-text then inverse, etc.)
hierarchy and spacing guidance
contrast-safe color assignments
This agent solved the “everything looks the same” problem by actively choosing from layout families and mixing them across sections.
3) Copywriter Agent
Goal: Write the content for each planned section in the right tone.
Input: strategy + style hints.
Output (JSON):
headline
preheader
section titles
body copy
CTA labels
Key constraint: the copywriter is not allowed to invent structure. It fills the structure already defined upstream.
4) Image Curator Agent
Goal: Turn content intent into image search signals and placements. Input: section plan + copy summary. Output (JSON):
per-section image keywords
recommended image aspect ratio
alt text
placement rules (e.g., at least one image-left and one image-right block)
The Image Curator Agent uses tool calling to access external image services, enabling it to fetch up-to-date and relevant images for each section. This tool calling process is analogous to the perception module in AI agent architecture, where information is gathered from the environment using digital or physical sensors and translated into a structured format.
Then a deterministic service builds/fetches image URLs (Unsplash-style keyword endpoints or API-based links). Important: I keep most URL construction outside LLM tokens when possible.
5) HTML Composer Agent
Goal: Generate robust email-safe HTML. This agent is responsible for the task execution of generating the final, production-ready HTML.
Input: strategy + style + copy + image plan + brand tokens.
Output: final HTML string with strict newsletter structure:
table-based layout
inline styles
mobile-safe stacking patterns
predictable section wrappers and IDs
This call is tightly constrained with a template contract to avoid random markup patterns that break in email clients.
6) Repair Agent (only when needed)
Goal: Fix only failed checks, not regenerate everything.
Input: previous HTML + validator errors.
Output: patched HTML.
This reduced latency spikes versus restarting the full chain.
4) The key technical decision: JSON contracts everywhere
Every non-HTML step returns strict JSON (schema-validated). That gave me:
deterministic orchestration
easier retries
explicit error locations
safer handoff between agents
This approach enables the use of feedback loops, where the output is iteratively validated and repaired as needed. AI agents can break down a high-level goal into smaller sub-tasks, execute them, and use these feedback loops to adjust their actions based on validation results.
I avoided free-form prose between agents because it created drift and ambiguity.
5) The critical questions I had to answer
These questions shaped the final workflow:
Should I keep a dedicated “architect” agent?
Initially yes, but it increased latency and token volume. When considering this, it’s important to evaluate whether using more capable models for certain responsibilities could improve agent performance across different architectures and domains. However, the performance of AI agents can degrade if the architecture is not aligned with the specific properties of the task.
Final choice: merge architecture responsibilities into Strategist + Style Director.Where should images be decided?
Not in the final HTML prompt.
Better: separate Image Curator first, then inject structured image data downstream.How do I guarantee section compliance with user prompts?
Add a section-count validator and hard checks for requested blocks (pros/cons, use cases, etc.).How do I avoid unreadable designs?
Enforce programmatic contrast checks (WCAG-like thresholds) and fallback text colors.How do I keep output diverse?
Use style “layout families” with selection logic and anti-repetition constraints.What if one agent fails JSON?
Add robust parsing, retries with simplified prompts, and repair-on-failure loops.
6) Reliability layer (non-LLM but essential)
The LLM pipeline is only half the solution. The other half is deterministic validation:
Schema validation for each JSON step
Contrast checks for headings/body text against backgrounds
Section coverage checks (required sections exist)
Image link checks (format + availability fallback)
HTML structure checks (table/tr/td consistency)
These automated validation processes minimize the need for human intervention, resulting in increased efficiency, improved accuracy, reduced manual intervention, and faster problem-solving.
If any check fails, the repair agent receives a minimal diff-style instruction set.
7) Prompt engineering patterns that worked
The following prompt engineering patterns represent key capabilities required for efficient and adaptive agentic workflows:
Role isolation: each agent has one job.
No cross-responsibility leakage: copywriter cannot redesign layout.
Hard output format: strict JSON with examples and required keys.
Bounded creativity: style director gets freedom within validated constraints.
Short memory handoffs: each agent receives only the data it needs.
For beginners: this is like a production line. One station cannot paint and weld and package at once. Specialization increases quality.
8) Latency vs quality trade-off
Multi-agent systems are slower than a single prompt. I accepted that because visual quality was priority #1.
Still, I cut unnecessary delay by:
removing redundant “architect” stage
keeping image URL generation partially deterministic
using targeted repair instead of full regeneration
limiting heavy context in each call
Using more capable models can improve output quality but may increase latency. Agentic AI workflows are designed to balance these trade-offs, functioning independently, adapting dynamically, and collaborating efficiently across various industries.
9) A minimal orchestrator sketch
At the core of this architecture, the orchestrator acts as a coding agent that coordinates multiple tools and specialized agents, enabling collaboration to solve complex problems that are too large for a single agent. This approach reflects the principles of Multi-Agent Systems, where collaboration among specialized agents is essential for efficiency and scalability.
async function generateNewsletter(prompt: string, brand: BrandPackage) {
const strategy = await strategist(prompt, brand.voice);
validateStrategy(strategy);
const style = await styleDirector(strategy, brand.designTokens);
validateStyle(style);
const copy = await copywriter(strategy, style, brand.voice);
validateCopy(copy, strategy);
const imagePlan = await imageCurator(strategy, copy);
const images = resolveImageUrls(imagePlan); // deterministic service
let html = await htmlComposer({ strategy, style, copy, images, brand });
let report = validateNewsletterHtml(html, strategy, style);
if (!report.ok) {
html = await repairAgent({ html, report, strategy, style, copy, brand });
report = validateNewsletterHtml(html, strategy, style);
}
if (!report.ok) throw new Error("Generation failed validation");
return html;
}
10) What changed in output quality
After this architecture shift:
layouts became more varied (true alternation, multi-column sections, richer composition)
prompts with explicit structure requirements were respected
visual readability improved significantly
regeneration became more predictable and debuggable
the new architecture enabled more informed decision making by allowing AI agents to analyze complex data and act accordingly to achieve predefined goals, enhancing decision-making processes
Evaluating Agent Systems
Evaluating agent systems is a critical step in ensuring that your AI solutions deliver reliable, high-quality results in real-world AI applications. Whether you’re working with single-agent or multi-agent systems, the evaluation process should be tailored to the architecture and intended use case.
For ai agent systems, key metrics include:
Accuracy: Does the agent produce correct and relevant output?
Completeness: Are all required tasks or sections covered?
Adaptability: Can the agent adjust to new prompts, data, or changing requirements?
The underlying agent architectures—whether reactive, deliberative, or hybrid—impact how agents operate and how they should be assessed. For example, reactive agents excel at fast, rule-based responses, while deliberative agents are better at planning and handling complex problem solving.
When evaluating multi-agent systems, additional factors come into play:
Multi-agent coordination: How well do agents collaborate and share information?
Conflict resolution: Can agents handle overlapping responsibilities or competing goals?
Scalability: Does adding more agents improve performance, or introduce bottlenecks?
Single-agent systems are typically easier to evaluate, focusing on the agent’s ability to execute tasks independently. In contrast, multi-agent systems require assessment of both individual agent performance and the effectiveness of their collaboration.
The choice of large language models and ai models also affects evaluation. It’s important to analyze how well these models integrate with your ai tools and whether your prompt engineering techniques yield consistent, high-quality agent output.
By systematically evaluating your agent systems, you can identify weaknesses, optimize workflows, and ensure your AI agents are robust enough for deployment in production environments. This process is essential for building agent systems that deliver real value in diverse, real-world scenarios.
Scaling Agent Systems
Scaling agent systems is where the true power of artificial intelligence comes into play—enabling you to tackle more complex tasks, automate repetitive tasks, and adapt to growing demands. The approach to scaling depends on whether you’re working with a single agent or a multi-agent system.
For multi-agent systems, scaling often means adding more specialized agents that can operate independently, each focused on a specific function. This modular approach allows you to distribute workload, improve efficiency, and handle a wider range of tasks. However, the key difference compared to single-agent scaling is the need for robust multi-agent coordination and collaboration. Agents must communicate effectively, avoid conflicts, and synchronize their actions to achieve shared goals.
Key strategies for scaling agent systems include:
Building agents with clear, well-defined roles and the ability to adapt dynamically to new data or environmental feedback.
Leveraging agent frameworks and cognitive architectures that support autonomous agent operation and real-time data processing.
Designing agentic workflows that allow agents to execute tasks using predefined rules, while still being able to learn from feedback and adjust their behavior.
Integrating tool usage and optimizing how agents interact with external tools or APIs to maximize throughput and minimize bottlenecks.
Incorporating human review and aligning with existing processes to ensure transparency, accountability, and high output quality.
For single-agent systems, scaling typically involves making the agent more capable—either by upgrading to more powerful models or by expanding its toolset. However, this approach can hit limits when faced with highly complex or parallelizable tasks, where a multi-agent approach offers more flexibility and resilience.
Next-generation agent systems will increasingly rely on advanced cognitive architectures and seamless integration with real-time data sources. This enables agents to operate independently, adapt to changing conditions, and deliver successful implementations across different domains.
Ultimately, scaling agent systems is about moving beyond traditional automation. By embracing agentic workflows and leveraging the strengths of both autonomous agents and human oversight, organizations can unlock new levels of efficiency, adaptability, and decision making in their AI-powered operations.
Final takeaway
Key Takeaways
Here are the key takeaways from this article: Agentic architectures are essential for supporting agentic behavior within AI agents. If you want production-grade AI-generated newsletters, don’t ask one model call to do everything.
Use a multi-agent pipeline with strict contracts + deterministic validation.
That combination is what made the AI Newsletter Agent actually usable, not just impressive in demos.