

The past few years have witnessed an unprecedented explosion in Artificial Intelligence, driven first by Large Language Models (LLMs) like GPT-3/4, then by Vision-Language Models (VLMs) such as GPT-4V, LLaVA, and Gemini. These breakthroughs have allowed AI to understand and generate human-like text and to interpret visual information with remarkable accuracy.
But the true revolution, especially for tangible systems that interact with our physical world, lies in the emergence of Vision-Language-Action (VLA) models. VLAs represent the cutting edge of AI, bridging the gap between perception, understanding, and physical interaction. They are poised to play a massive, transformative role in the future of robotics and, by extension, the entire landscape of Cyber-Physical Systems (CPS).
From LLMs to VLAs: The Exponential Leap
Let’s quickly trace the lineage that led to VLAs:
Large Language Models (LLMs): These models are trained on vast amounts of text data, enabling them to understand, generate, and reason about human language. They can answer questions, summarize documents, write code, and engage in complex conversations. However, they are inherently “blind” to the visual world and cannot directly perform physical actions.
Vision-Language Models (VLMs): Building upon LLMs, VLMs integrate a visual encoder, allowing them to process both text and images. They can describe images, answer questions about visual content, and perform tasks like visual question answering (VQA) or image captioning. While they “see” and “understand” both modalities, they still lack the direct ability to act in the physical world.
Vision-Language-Action (VLAs): This is the game-changer. VLAs take the understanding capabilities of VLMs (language + vision) and extend them to directly control physical systems. They are trained not just on text and image data, but also on demonstrations of actions in various environments. This allows them to:
Perceive: Understand the scene through cameras and other sensors.
Comprehend: Interpret human language instructions in the context of that scene.
Reason: Plan a sequence of physical actions to fulfill the instruction.
Act: Execute those actions using robotic manipulators, grippers, or mobile platforms.
The exponential growth comes from the realization that by connecting rich, human-like reasoning (language) and comprehensive perception (vision) directly to the execution layer (action), we can unlock unprecedented levels of autonomy and adaptability in machines.
Why VLAs are a Game-Changer for Robotics
Traditional robotics has relied on highly engineered, brittle solutions. A robot might be programmed to pick up a specific red block from a specific location. If the block is green, or in a slightly different position, the robot fails. VLAs change this paradigm entirely.
- Natural Language Instruction: Imagine telling a robot, “Please put the apple in the blue bowl on the left side of the table.”
A traditional robot needs precise coordinates and object IDs.
A VLA-powered robot can parse this natural language, visually identify the “apple” and the “blue bowl on the left side,” and then plan the necessary sequence of grasping and placement actions. This democratizes human-robot interaction.
Generalization to Novel Objects and Environments: VLAs learn from diverse datasets, allowing them to generalize. If a robot is trained to pick up various household items, it can likely pick up a new item it hasn’t seen before, as long as its visual characteristics are within its learned distribution. This significantly reduces programming effort and increases adaptability.
Complex Task Planning and Error Recovery: VLAs can interpret high-level goals (“Make coffee”) and break them down into sub-tasks (“Pick up mug,” “Place under dispenser,” “Press button”). If an error occurs (e.g., the mug slips), the VLA can leverage its visual understanding to detect the error and attempt to recover (“Regrasp mug”).
Embodied Intelligence: This is the core. VLAs enable “embodied AI”—intelligence that is situated in a physical body and interacts with the world through that body. This means learning from real-world physics, unexpected events, and the nuances of physical manipulation, leading to more robust and versatile robots.
VLAs in Cyber-Physical Systems: The Future of Interaction
The impact of VLAs extends far beyond individual robots; they are set to revolutionize the entire concept of Cyber-Physical Systems (CPS). CPS inherently integrate computation with physical processes, and VLAs provide a powerful, intelligent interface for this integration.
Examples of VLA-Powered CPS:
- Smart Manufacturing and Industry 5.0:
Current CPS: Automated arms follow precise, pre-programmed paths to assemble a product.
VLA-Powered CPS: A human operator can instruct a robotic arm, “Assemble this new variant using the components in bin A and tools from the top shelf.” The VLA robot visually identifies components, plans the assembly sequence, and adapts to slight variations in component placement or tool availability. This enables rapid retooling and agile manufacturing.
- Autonomous Navigation and Logistics:
Current CPS: Delivery robots follow GPS waypoints and use Lidar to avoid static obstacles.
VLA-Powered CPS: A drone is instructed, “Deliver this package to the house with the red door, avoid the puddles in the driveway, and place it gently on the porch swing.” The VLA drone interprets the complex visual and linguistic cues, plans a dynamic path, and executes a precise landing.
Traffic Management: Imagine a VLA system observing live traffic camera feeds. It doesn’t just identify congestion; it interprets context (e.g., “There’s a broken-down truck on the left lane”) and then proposes intelligent, nuanced changes to traffic light timings or rerouting suggestions that go beyond simple rules.
- Healthcare and Assisted Living:
Current CPS: Robotic exoskeletons assist patients with predefined movements.
VLA-Powered CPS: A care robot can be instructed, “Hand me the blue medication bottle from the bedside table” or “Help me sit up gently.” The VLA visually identifies objects, assesses the patient’s posture, and performs actions with nuanced force control.
- Environmental Monitoring and Response:
Current CPS: Drones collect data for mapping forests or inspecting infrastructure.
VLA-Powered CPS: A drone is dispatched with the instruction, “Inspect the north side of the bridge for any cracks, paying close attention to the support beams. If you see anything unusual, take detailed photos and highlight the area.” The VLA drone autonomously navigates, performs visual inspections based on textual criteria, and identifies anomalies without constant human teleoperation.
The VLA Architecture: Integrating Perception, Language, and Control
A VLA model typically involves several interconnected components:
Vision Encoder: Processes raw sensory data (images, depth maps, point clouds) into a rich, abstract representation. This might leverage architectures like Vision Transformers.
Language Encoder: Processes human instructions or queries into a contextualized language representation. This is typically a component borrowed from LLMs.
Multimodal Fusion: Combines the visual and language representations into a shared understanding of the scene and the task. This is the VLM part.
Action Planner/Policy Network: Based on the fused multimodal understanding, this component generates a sequence of high-level or low-level actions. This is often an RL (Reinforcement Learning) policy or a planning module that considers the robot’s kinematics and dynamics.
Robot Controller/Actuators: Executes the generated actions in the physical world.
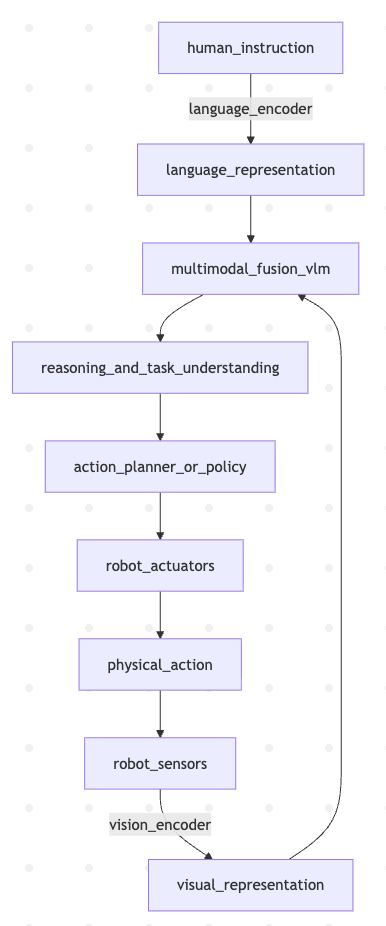
Schematic: The VLA Feedback Loop
This diagram illustrates how a VLA model integrates human instruction with sensory input to produce physical actions, completing the cyber-physical feedback loop.
Challenges and the Road Ahead
While VLAs promise a revolutionary future, significant challenges remain:
Data Scarcity for Action: Training VLAs requires vast amounts of multimodal data linking observations to actions. Collecting high-quality, diverse robotic demonstration data is expensive and time-consuming.
Safety and Reliability: Deploying autonomous systems that interpret open-ended instructions requires robust safety guarantees and predictable behavior, especially in critical applications.
Real-Time Performance: Executing complex VLA models on embedded robot hardware while maintaining real-time control is computationally intensive. Edge AI optimization will be crucial.
Ethical Considerations: As robots become more intelligent and autonomous, ethical questions around responsibility, bias, and the impact on labor forces will intensify.
Conclusion
Vision-Language-Action models represent the next frontier in AI, moving us beyond passive understanding to active, intelligent interaction with the physical world. By seamlessly integrating the rich reasoning capabilities of LLMs and VLMs with robotic control, VLAs are poised to transform not just the field of robotics, but also the very fabric of Cyber-Physical Systems. They promise a future where our machines are not just smart, but truly intuitive, adaptable, and capable of understanding our world and our intentions in a profoundly human-like way. The era of truly intelligent, embodied CPS is just beginning.