Local AI is evolving incredibly fast right now.
For the past two years, most improvements in local LLM performance came from familiar optimizations:
- quantization
- GGUF compression
- CUDA and Metal kernels
- KV cache improvements
- Flash Attention
- memory optimizations
But something deeper is now starting to happen.
Instead of only optimizing runtimes and hardware utilization, researchers and inference engineers are beginning to redesign how models generate text itself.
And one of the most important developments in that direction is Multi-Token Prediction (MTP).
Recently, Julien Chaumond, CTO at Hugging Face, highlighted that MTP support is expected to land in llama.cpp, potentially bringing massive inference speed improvements to compatible models.
The claim is simple:
A local model generating 20 tokens/sec today could potentially reach 40 tokens/sec in many scenarios.
If that sounds dramatic, it is because it actually is.
This is not just another small optimization.
This could fundamentally improve how responsive local AI feels on:
- Apple Silicon Macs
- NVIDIA RTX GPUs
- AMD Radeon GPUs
- local servers
- offline AI assistants
- coding copilots
- edge AI systems
And more importantly, it reflects a much bigger trend happening across the entire open-source AI ecosystem.
Key Takeaways
- Multi-Token Prediction (MTP) allows LLMs to predict multiple future tokens simultaneously.
- MTP can significantly reduce local inference latency.
llama.cppsupport for MTP could dramatically improve tokens-per-second performance.- Apple Silicon, RTX, and Radeon GPUs may all benefit from these optimizations.
- Qwen and Gemma are among the first major open model families embracing MTP.
- Inference architecture is becoming just as important as benchmark intelligence.
What Is Multi-Token Prediction (MTP)?
To understand why MTP matters, we first need to understand how most LLMs currently work.
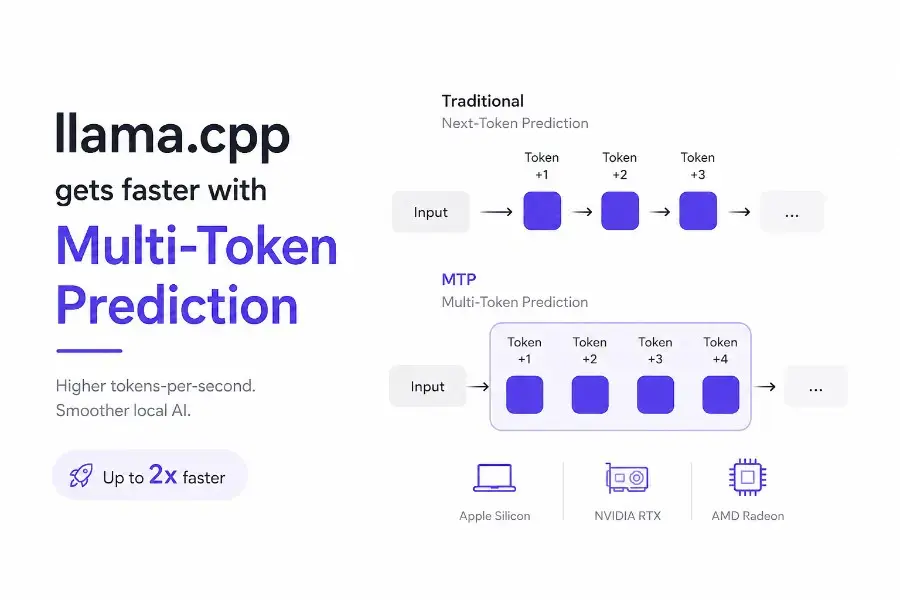
Traditional language models generate text one token at a time.
For example:
“The capital of France is”
The model predicts:
“Paris”
Then it predicts the next token.
Then the next.
Then the next.
This is called next-token prediction.
It works extremely well, but it also creates an important limitation:
Inference becomes inherently sequential.
Even with a powerful GPU, the model still needs to repeatedly execute expensive decoding steps one token at a time.
That creates latency.
And latency is one of the biggest challenges in local AI.
How Multi-Token Prediction Works
Multi-Token Prediction changes this approach.
Instead of predicting only the next token, the model learns to predict several future tokens simultaneously.
At a high level, MTP introduces additional prediction heads capable of forecasting:
- token +1
- token +2
- token +3
- token +4
during the same forward pass.
A simplified comparison looks like this:
| Traditional LLM | MTP-enabled LLM |
|---|---|
| Predicts one token | Predicts multiple future tokens |
| Sequential decoding | Parallel speculative decoding |
| Higher latency | Lower latency |
| More forward passes | Better efficiency per pass |
This matters because modern LLM inference is often not limited by raw compute.
It is limited by memory movement.
Google explains this particularly well in their recent work around Gemma and MTP:
https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/
Large models spend enormous amounts of time moving weights between memory and compute units just to generate one token.
MTP helps improve efficiency by extracting more useful output from each expensive pass through the model.
That is why the potential performance gains are so significant.
MTP vs Speculative Decoding
If you have been following inference optimization recently, you have probably heard about speculative decoding.
The two concepts are closely related.
What Is Speculative Decoding?
Speculative decoding works like this:
- A smaller and faster draft model predicts several future tokens
- The larger target model verifies those predictions
- Correct predictions are accepted
- Incorrect predictions are corrected
This already provides major latency improvements.
A beginner-friendly analogy would be:
Imagine a junior engineer drafting code while a senior engineer quickly validates it.
The senior engineer no longer writes every line from scratch.
That is speculative decoding.
What Makes MTP Different?
What makes MTP especially interesting is that the drafting capability can become integrated directly into the architecture itself.
That means:
- fewer moving parts
- tighter optimization
- lower overhead
- better deployment simplicity
- improved efficiency
This is one reason why inference engineers are so excited about MTP support in llama.cpp.
Why This Matters for llama.cpp
llama.cpp has quietly become one of the most important projects in the entire local AI ecosystem.
It powers:
- desktop AI apps
- GGUF inference
- local coding assistants
- offline chatbots
- Apple Silicon workflows
- CUDA inference
- Vulkan acceleration
- embedded AI systems
A huge part of modern local AI infrastructure ultimately depends on llama.cpp.
So when a major inference optimization lands there, it impacts the entire ecosystem.
That is why this MTP development is such a big deal.
Why Apple Silicon Users Should Pay Attention
Apple Silicon machines are already surprisingly good for local AI workloads.
Especially because of:
- unified memory
- high memory bandwidth
- efficient Metal acceleration
- strong power efficiency
But even powerful M-series Macs still suffer from decoding latency on larger models.
MTP directly targets this bottleneck.
That means models like:
- Qwen
- Gemma
- Llama
- DeepSeek
- coding-oriented models
could feel dramatically faster and more responsive on existing hardware.
And honestly, responsiveness matters more than raw benchmark scores for most real-world workflows.
A model that feels instant is often more useful than a model that is slightly smarter but significantly slower.
Why RTX and Radeon GPUs Also Benefit
This is not just an Apple Silicon story.
NVIDIA RTX and AMD Radeon users should also benefit significantly.
Especially for workloads like:
- local copilots
- AI coding assistants
- RAG pipelines
- local agents
- interactive chat
- document analysis
Modern inference workloads are increasingly bottlenecked by:
- VRAM bandwidth
- KV cache management
- memory transfer costs
not only raw FLOPS.
MTP improves efficiency at the decoding layer itself.
That is why the performance gains can be substantial even on already powerful GPUs.
Why Qwen and Gemma Matter So Much
One reason this MTP wave feels particularly important is because it is connected to serious open model families.
Qwen
Qwen models are rapidly becoming some of the strongest open-source LLMs for:
- coding
- reasoning
- multilingual tasks
- long-context inference
- multimodal workflows
I recently wrote a deeper technical breakdown about Qwen’s evolving multimodal and agent-native architecture here:
Qwen 3.5 VLM just dropped — and it’s a very “agent-native” kind of model
Official Qwen models:
https://huggingface.co/Qwen
Gemma 4
Google is also aggressively pushing toward more efficient inference architectures with Gemma.
Their recent Gemma 4 work around speculative decoding and MTP is particularly interesting:
https://deepmind.google/models/gemma/gemma-4/
If you want a deeper dive into the Gemma 4 architecture, benchmarks, limitations, and deployment implications, I also published a full technical analysis here:
Gemma 4 Explained - Architecture, Benchmarks, Limits, and Real-World Use Cases
What matters most here is the larger trend:
Open models are no longer only competing on intelligence.
They are competing on inference efficiency.
Future comparisons will increasingly ask:
- Which model serves fastest?
- Which architecture minimizes latency?
- Which model works best locally?
- Which model is easiest to deploy efficiently?
That is a massive shift.
Why Local AI Is Entering a New Era
For years, local AI optimization mostly focused on runtime tricks:
- quantization
- Flash Attention
- CUDA kernels
- GGUF
- KV cache optimization
Those optimizations are still extremely important.
But now the models themselves are evolving to become more inference-efficient.
That changes the game.
And this trend goes far beyond chatbots.
It connects directly to:
- edge AI
- robotics
- on-device assistants
- autonomous systems
- Physical AI
I explored this broader shift toward hardware-constrained AI systems in more depth here:
What Physical AI Really Means for Robotics and Cyber-Physical Systems
Latency and efficiency are becoming first-class architectural concerns.
Not just deployment details.
Important Reality Check: MTP Is Not Magic
It is important to stay realistic.
MTP is extremely promising, but speedups depend on several factors.
The Model Must Support It
Not every GGUF model automatically becomes faster.
The architecture itself must support MTP or compatible speculative decoding workflows.
Acceptance Rates Matter
The more accurate the drafted tokens are:
- the larger the speedup
If predictions are frequently rejected:
- gains shrink
Workload Matters
MTP is especially attractive for:
- interactive chat
- coding assistants
- low-concurrency workloads
- personal AI systems
Under heavy batching and high concurrency, gains may vary.
What Beginners Should Understand
If you are new to local AI, here is the simplified explanation.
Traditional LLMs generate text one token at a time.
That is slow.
Multi-Token Prediction helps models predict and validate several future tokens simultaneously.
This reduces latency and increases tokens-per-second.
For local AI users, this means:
- faster chats
- more responsive copilots
- smoother coding assistants
- better local agents
- improved hardware utilization
without necessarily buying a new GPU.
And honestly, that is one of the most exciting parts.
Software architecture is starting to unlock performance gains that previously required hardware upgrades.
What I Expect Next
I expect MTP to become one of the default selling points of future open models.
Soon, model cards may advertise:
- native MTP support
- speculative decoding compatibility
- latency benchmarks
- acceptance rates
- Apple Silicon optimization
- RTX efficiency
- local inference performance
Inference engineering is rapidly becoming just as important as benchmark intelligence itself.
And for local AI users, that is excellent news.
Final Thoughts
Multi-Token Prediction is not just another incremental optimization.
It represents a deeper evolution in how open-source LLMs are designed and served.
For years, local AI users relied mostly on:
- better GPUs
- larger VRAM pools
- quantization tricks
- optimized runtimes
Now the models themselves are becoming inference-aware.
That is the truly important shift.
If MTP support lands cleanly in llama.cpp, many existing machines could suddenly feel dramatically faster.
Not because the hardware changed.
But because the inference architecture became smarter.
And honestly, I think this is one of the most important trends in AI right now.
FAQ
What is Multi-Token Prediction (MTP)?
Multi-Token Prediction is a technique where an LLM predicts multiple future tokens simultaneously instead of generating only one token at a time.
Does MTP make llama.cpp faster?
Yes. MTP support in llama.cpp could significantly improve local inference speed for compatible models such as Qwen and Gemma.
Is MTP the same as speculative decoding?
Not exactly. MTP is closely related to speculative decoding but can integrate drafting capabilities directly into the model architecture itself.
Which hardware benefits from MTP?
Apple Silicon Macs, NVIDIA RTX GPUs, and AMD Radeon GPUs can all benefit from reduced inference latency.
Will every GGUF model support MTP?
No. The model architecture itself must support Multi-Token Prediction or compatible speculative decoding workflows.