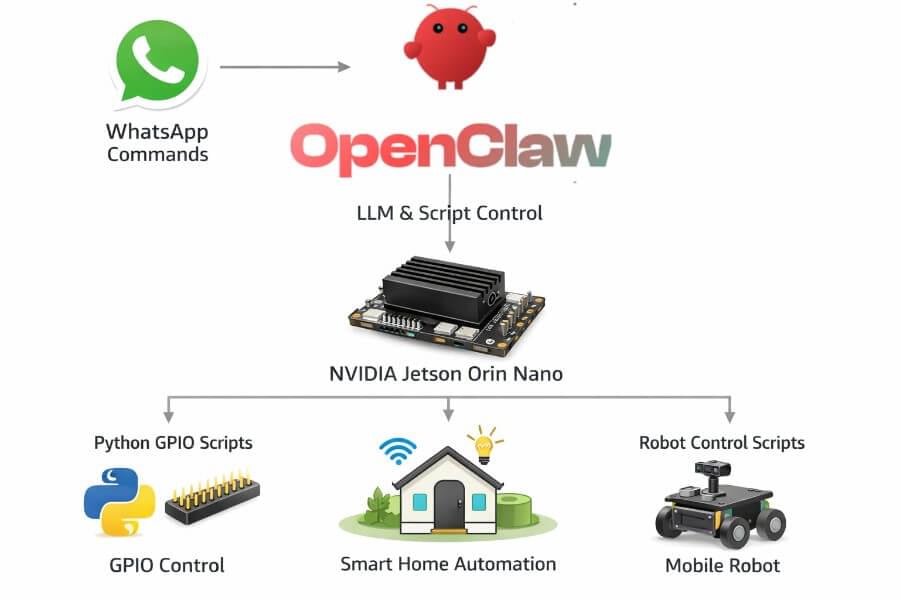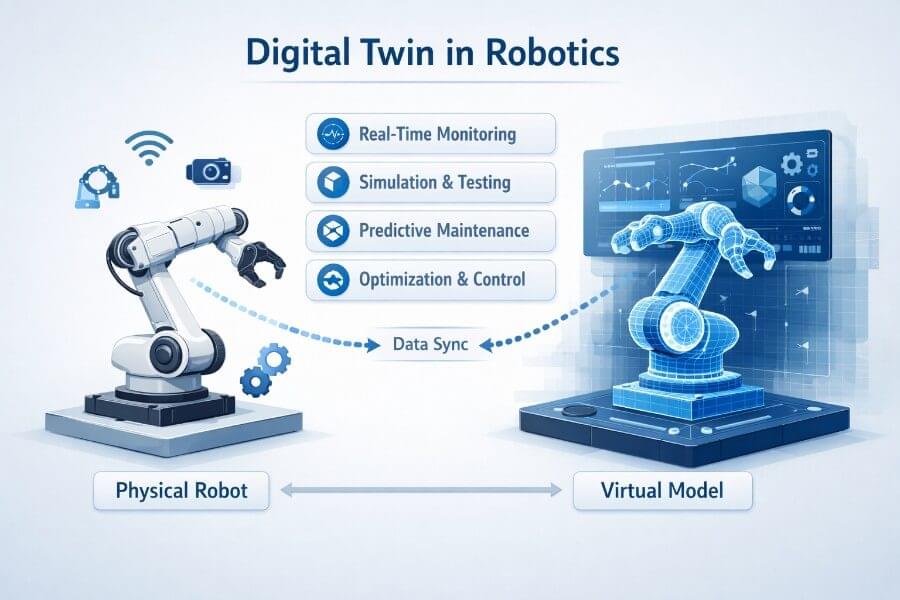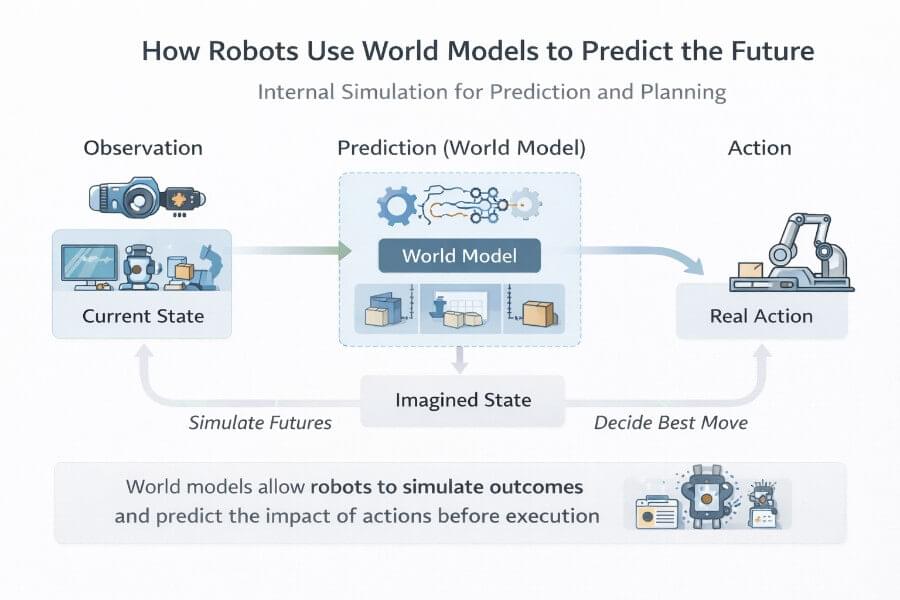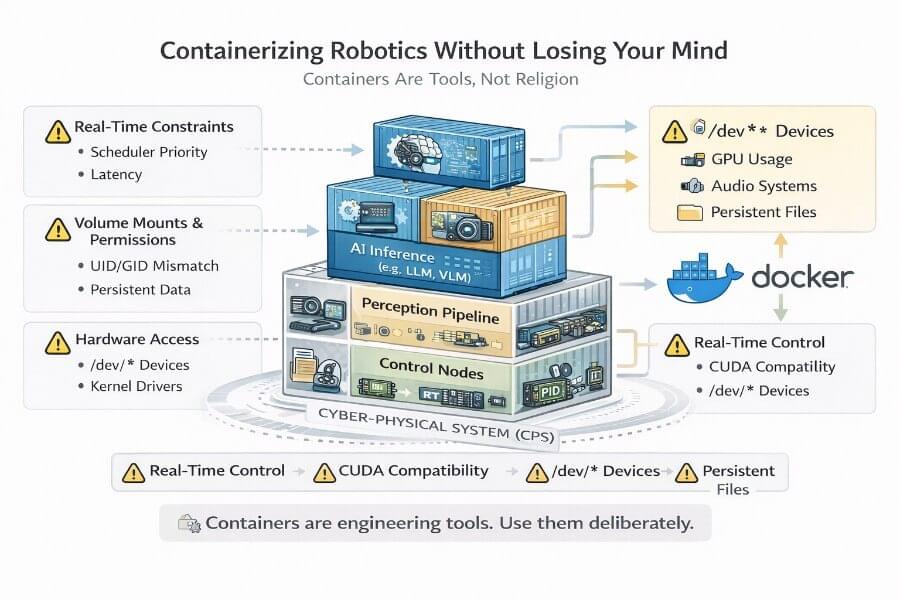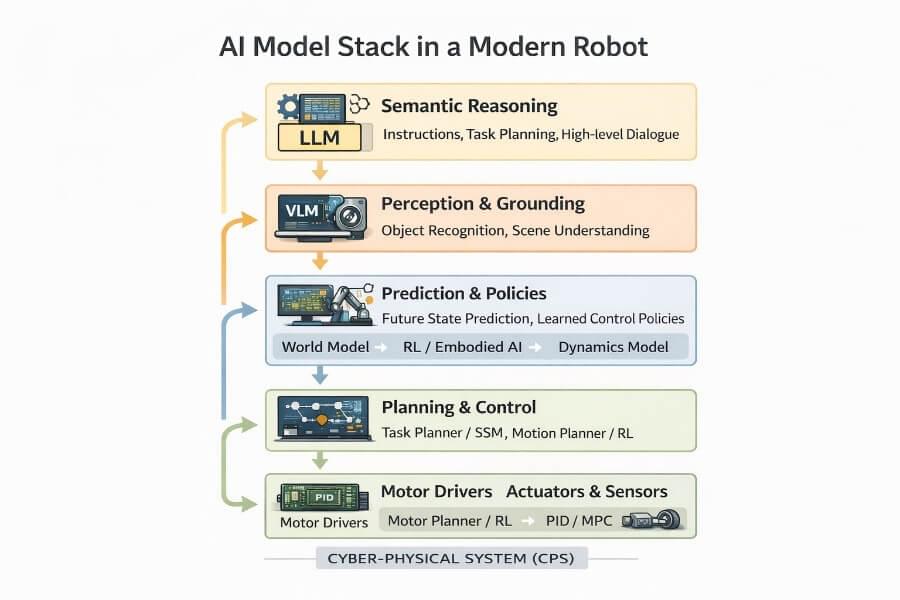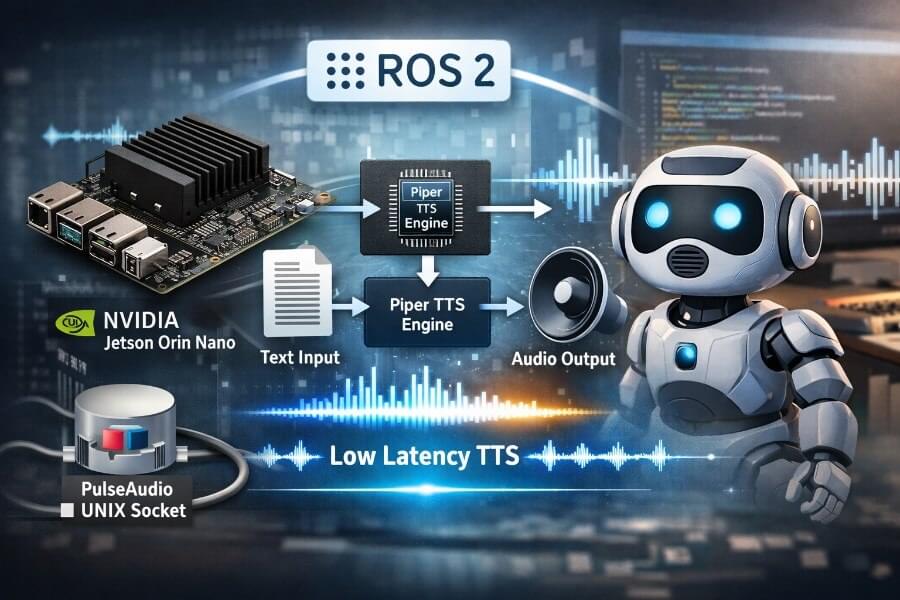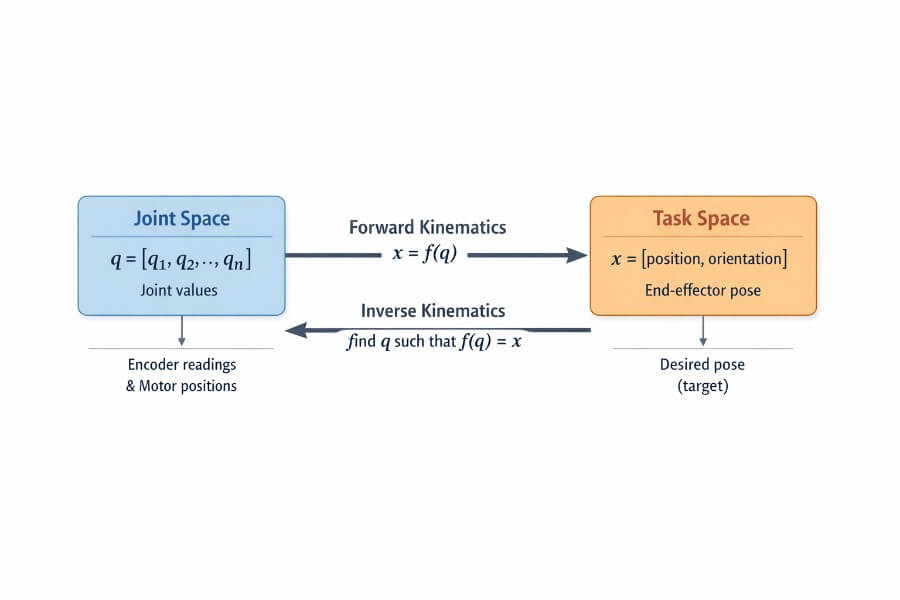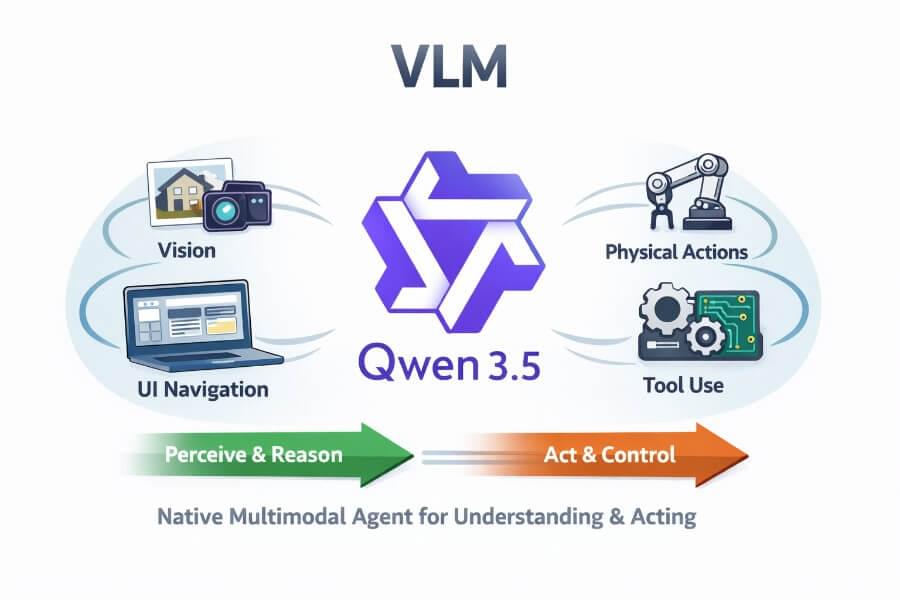
A few days ago, Alibaba’s Qwen team released Qwen 3.5, and it’s one of those launches that quietly changes the “default mental model” of what a VLM is supposed to be. Not just a model that can see, but a model that’s clearly being positioned as a native multimodal agent: something that can look at a UI, reason over it, decide what to do next, and (crucially) do so efficiently enough that you can imagine it running in production without your GPU bill turning into performance art.