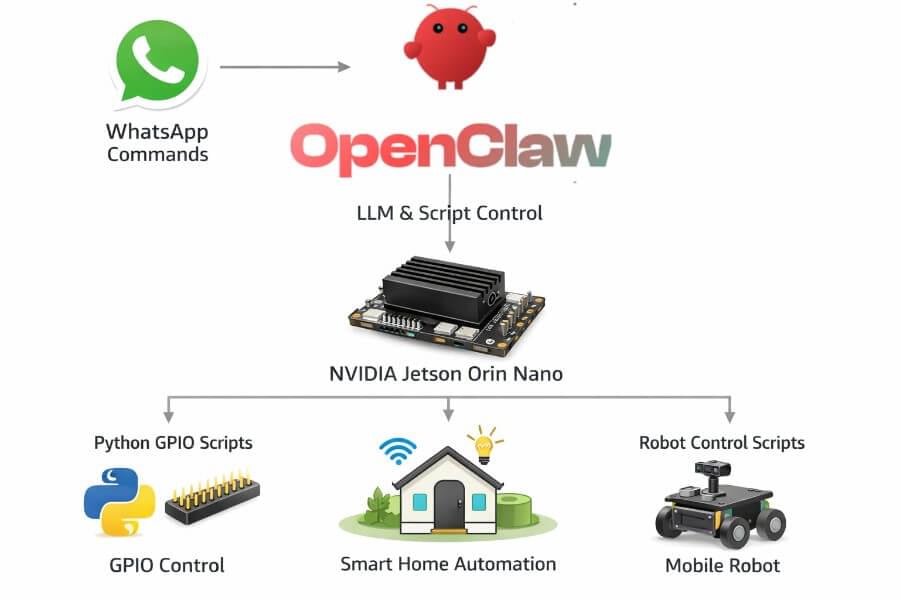
OpenClaw on Jetson is best understood as a local AI agent control plane. The Jetson hosts the runtime close to sensors, files, scripts, ROS 2 nodes, and hardware bridges. OpenClaw gives that runtime four practical building blocks: durable memory, a dashboard, skills and tools, and MCP interoperability.

Building a Local Robot Brain on Jetson Orin Nano Super with ROS 2, Whisper, Llama, Piper TTS and an LLM Bridge
This article documents the missing “brain” layer of my local robot assistant runtime.
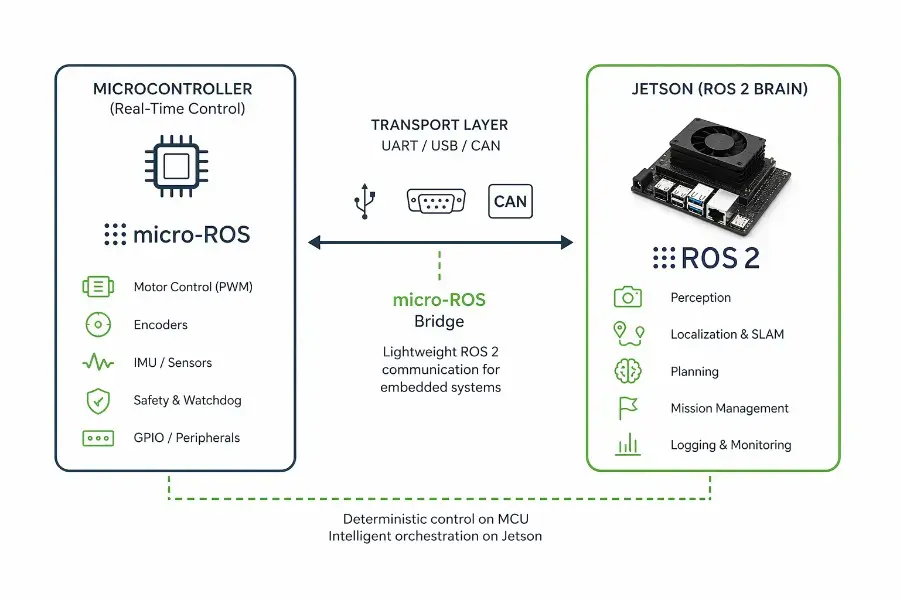
micro-ROS - connecting a real-time microcontroller to a ROS 2 brain on Jetson
If you are building a real robot, you eventually hit the same architectural wall.

Create Your First OpenClaw Skill to Control a Robot or Sensor
Installing OpenClaw is the easy part. Making it do something useful in the physical world is where things get interesting.
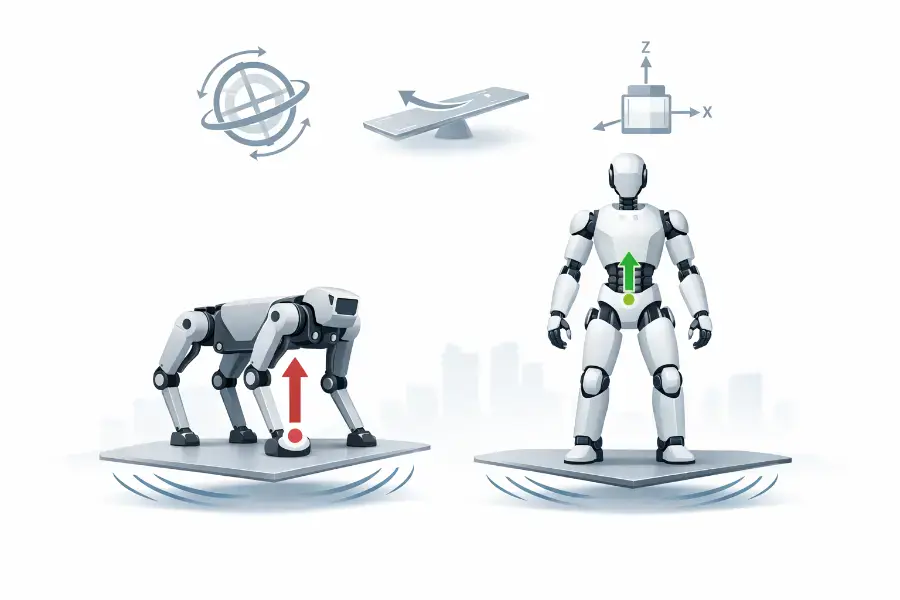
How Quadruped and Humanoid Robots Stay Balanced
Legged robots look magical when they recover from a shove, step over debris, or keep walking on uneven ground. But their balance is not magic. It is the result of layered engineering: mechanics, sensing, estimation, dynamics, control, planning, and increasingly learning.

Muse Spark Explained - Architecture, Benchmarks, Limits, and Real-World Use Cases
On April 8, 2026, Meta released Muse Spark, the first model in its new Muse family and the first major model launch from Meta Superintelligence Labs.
This is not just another chatbot release.
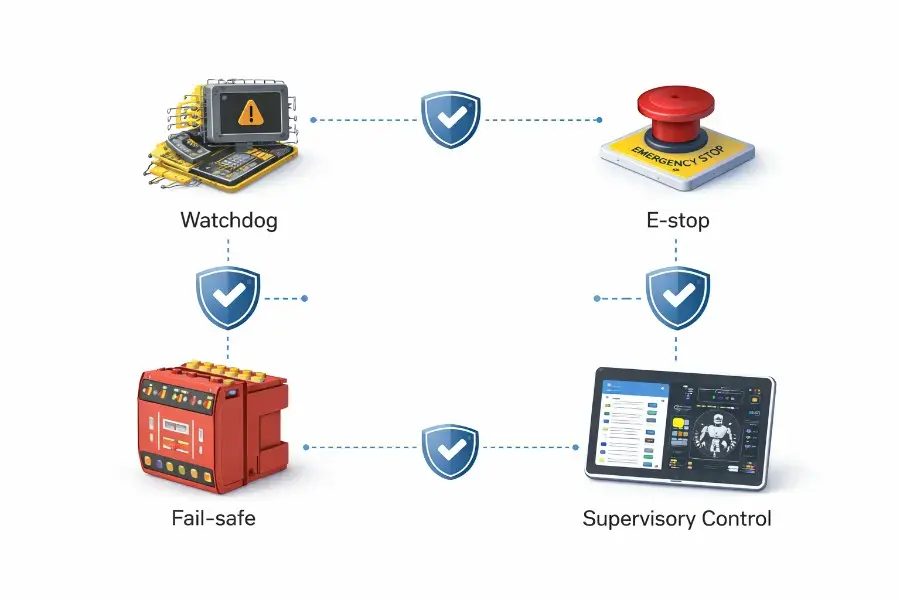
Robot Safety Architecture - Watchdogs, E-Stops, Failsafes, and Supervisory Control
The fastest way to misunderstand robot safety is to treat it as a button.
It is not.
A red mushroom emergency stop matters. A watchdog matters. A failsafe matters. But none of them, alone, is robot safety architecture. Safety in robotics is not a feature. It is not a checkbox. It is not a clever prompt, a neat ROS node, or a good-looking demo video. It is an architectural property of the whole cyber-physical system.

Gemma 4 Explained - Architecture, Benchmarks, Limits, and Real-World Use Cases
Google publicly announced Gemma 4 on April 2, 2026, while Google’s own Gemma release log lists March 31, 2026 as the checkpoint release date. The date discrepancy is minor. The strategic point is not.

Real-Time Linux for Robotics - Latency, Jitter, Scheduling, and What Actually Breaks
If you build robots long enough, you eventually stop asking “is it fast?” and start asking “is it predictable?” That is the real question.
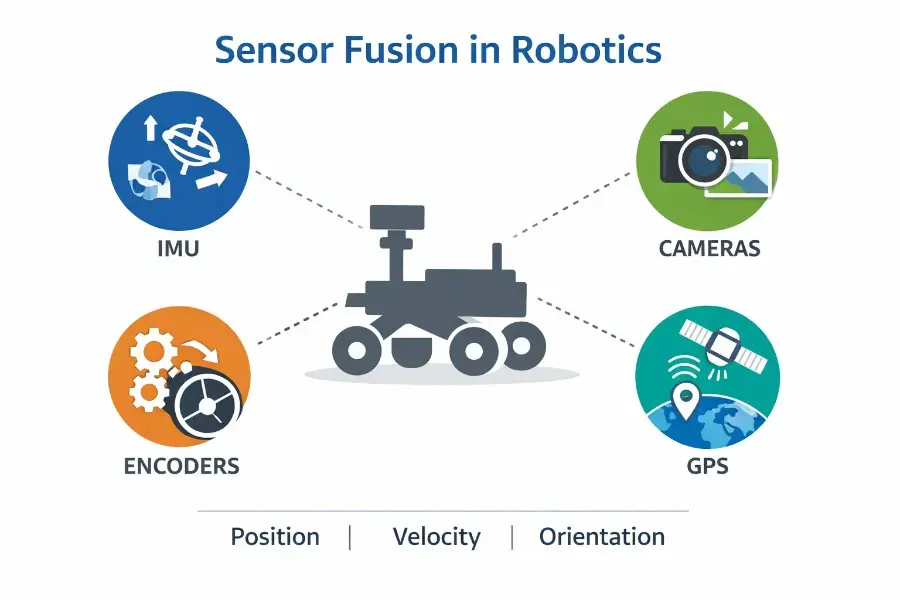
What Is Sensor Fusion in Robotics? How Robots Combine IMUs, Cameras, Encoders, and GPS
If you build robots long enough, you realize something uncomfortable very quickly:
a robot never directly “knows” its own state.
It does not perceive position, orientation, or velocity as ground truth. It only receives fragments of reality.