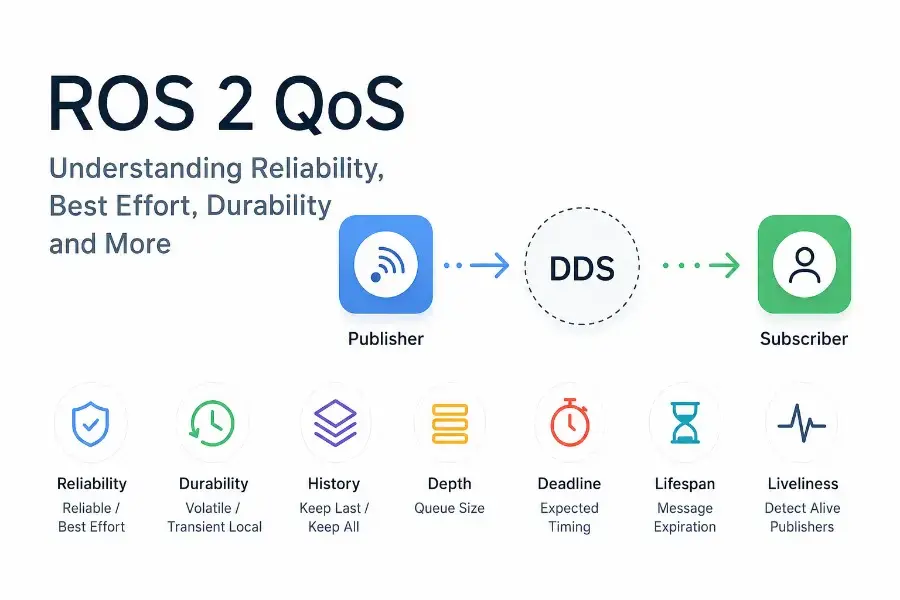
If you work with ROS 2 long enough, eventually something “impossible” happens.
Your subscriber stops receiving messages.
RViz sees a topic but not the data.
ros2 topic echo works perfectly on one machine but fails on another.
A camera stream randomly drops frames during navigation.
A late-joining node never receives the latest robot state.
Or worse: everything looks healthy in the ROS graph while the robot behaves inconsistently.
At first, most developers blame the node itself, the DDS vendor, the network, or even ROS 2 entirely.
But in a huge number of real systems, the root cause is actually much simpler:
QoS.
ROS 2 inherited DDS-level Quality of Service policies because robotics systems do not all share the same communication constraints. A 60 FPS stereo camera stream, a LiDAR publisher running over Wi-Fi, a motor emergency stop topic, and a static map server should not all behave identically on the network layer. Some flows prioritize freshness, others prioritize reliability, and others need deterministic startup synchronization.
QoS exists precisely to express those differences.
The problem is that most ROS 2 developers discover QoS only after spending hours debugging “random” behavior in a distributed graph.
And that is why this article exists.
If you already read my article on ROS 2 architecture patterns that scale, this is the practical networking continuation. Architecture diagrams are useful, but eventually every production ROS 2 system reaches the point where communication behavior itself becomes part of the architecture.
The official ROS 2 documentation describes QoS policies as the mechanism controlling reliability, durability, queueing, and delivery guarantees between publishers and subscribers. In practice, QoS is much more than a middleware detail. It is a communication contract that directly affects latency, startup behavior, bandwidth usage, synchronization, and fault tolerance.
Once you understand that, many mysterious ROS 2 bugs suddenly stop looking mysterious.
Why QoS Exists in ROS 2
ROS 1 intentionally optimized for simplicity. Publishers and subscribers exchanged messages with relatively little configuration, which made prototyping extremely fast and accessible. For academic robotics and small local systems, that model worked surprisingly well.
But ROS 1 also had limitations that became increasingly painful in production robotics systems.
Distributed deployments over unreliable networks were difficult to scale. Real-time communication guarantees were limited. Wireless communication could become unstable under heavy traffic. High-frequency sensor streams and mission-critical commands were handled almost identically despite having radically different requirements.
ROS 2 moved to DDS specifically to solve those problems.
DDS was designed for distributed, fault-tolerant, real-time capable systems. Instead of assuming all data should behave the same way, DDS allows developers to define communication policies explicitly.
That flexibility is powerful, but it also introduces complexity.
A LiDAR stream at 20 Hz over Wi-Fi does not have the same constraints as /cmd_vel. A static transform does not behave like an RGB camera stream. A robot localization estimate does not need the same buffering strategy as a debug topic.
QoS exists because robotics systems are inherently heterogeneous.
And once systems become distributed, communication design becomes part of the software architecture itself.
The Most Important Mental Model in ROS 2
Most developers initially think of a ROS 2 topic as simply:
- a topic name,
- and a message type.
But in reality, a ROS 2 topic is:
- a topic name,
- a message type,
- and a QoS contract.
That distinction matters enormously.
Two nodes may agree perfectly on the topic name and message type while still being completely unable to communicate.
This is one of the biggest conceptual differences compared to ROS 1.
In ROS 2, communication compatibility depends not only on the payload definition but also on the transport policies attached to that payload. If the QoS settings between publishers and subscribers are incompatible, DDS may refuse to establish communication entirely.
The result is extremely confusing when you first encounter it.
The topic appears in the graph.
Discovery works.
Nodes can see each other.
And yet messages never arrive.
Understanding this single idea already explains a large percentage of “ROS 2 is behaving weirdly” situations.
Reliability — Reliable vs Best Effort
The reliability policy is usually the first QoS setting developers encounter, and it is responsible for a huge amount of confusion in real systems.
At a high level, reliability defines whether DDS should guarantee message delivery or prioritize low-latency transmission even if packets are occasionally lost.
Reliable communication behaves conceptually closer to TCP. DDS tracks whether messages successfully arrived and retransmits packets if necessary. This improves consistency and reduces the probability of data loss, which is critical for many robotics workloads.
For example, actuator commands, mission events, robot state synchronization, diagnostics, and navigation coordination often require reliable communication because losing information may create inconsistent system state or dangerous robot behavior.
But reliable delivery is not free.
Guaranteeing delivery introduces retransmissions, buffering, bookkeeping overhead, and additional network pressure. On overloaded systems or unstable wireless links, reliable QoS can actually increase latency significantly because middleware continues retrying old packets.
And this is where many robotics developers discover an important reality:
in robotics, stale data is often worse than missing data.
A delayed camera frame may be completely useless for obstacle avoidance. An old LiDAR scan can produce incorrect localization corrections. A control loop operating on outdated sensor data may become unstable even if no packets were technically lost.
That is why ROS 2 also supports best effort communication.
Best effort behaves more like UDP semantics. DDS attempts to deliver data but does not endlessly retry when packets disappear. The priority becomes freshness instead of guaranteed replay.
For high-frequency sensor streams, this is often exactly the correct tradeoff.
Cameras, IMUs, LiDAR streams, depth images, and telemetry frequently benefit more from receiving the newest available sample than from preserving every historical frame. In real deployments, especially over Wi-Fi or embedded networks, best effort communication often produces lower latency and more stable system behavior.
Ironically, developers frequently assume “reliable” automatically means “better,” while many production robots actually perform more consistently using best effort for perception pipelines.
Why RViz and Camera Streams Break So Often
One of the most common ROS 2 debugging situations involves cameras and RViz.
A camera driver publishes images normally.
The topic appears correctly in ros2 topic list.
But RViz shows no image at all.
Or a custom subscriber receives nothing despite the graph looking healthy.
In many cases, the issue is simply a QoS mismatch.
Many camera drivers publish using best_effort because high-rate image streams benefit from low-latency transmission. Meanwhile, visualization tools or custom subscribers sometimes default to reliable.
The publisher and subscriber then fail QoS negotiation silently.
The result is confusing because discovery still succeeds. ROS 2 knows the topic exists. Nodes can detect each other. But DDS refuses the actual communication path because the policies are incompatible.
This is why one of the most important debugging commands in ROS 2 is:
1 | ros2 topic info /camera/image_raw --verbose |
This command exposes the actual QoS settings being used by publishers and subscribers, including reliability, durability, history, and queue depth.
Once you start using this command systematically, an enormous percentage of ROS 2 communication bugs suddenly become understandable.
Durability — The Late Joiner Problem
Durability is another QoS policy that initially feels abstract until you encounter a real distributed robotics system.
Durability controls whether messages survive for future subscribers that were not connected when the original publication occurred.
The default policy is called volatile.
Volatile durability means messages are delivered only to currently active subscribers. If a node joins later, previously published data is gone forever.
For live sensor streams, this behavior makes perfect sense. A camera frame from ten seconds ago is usually irrelevant. An IMU sample from the past is rarely useful after the fact.
But some robotics data behaves differently.
Static transforms, maps, calibration parameters, robot configuration, and initialization state often need to be available immediately to late-joining nodes.
This is where transient_local durability becomes critical.
Transient local durability allows publishers to retain recent messages specifically for future subscribers. When a new node joins, DDS immediately delivers the retained state without waiting for another publication cycle.
This behavior becomes extremely important in large ROS 2 systems where startup order is unpredictable.
Imagine a mapping node publishing /map only every few seconds. If the navigation stack launches slightly later using volatile durability, it may initially receive nothing at all. With transient local durability, DDS immediately forwards the latest retained map to the late subscriber.
That single QoS policy can completely change startup reliability.
ROS 2 itself already uses this pattern internally. The /tf_static topic relies on transient local durability because static transforms must remain available to nodes joining the graph later. Without that behavior, newly started nodes would miss critical frame relationships entirely.
This concept also connects directly with frame management and calibration workflows discussed in my article on ROS 2 camera calibration, TF2, and optical frames.
History and Depth — The Hidden Queues Nobody Thinks About
History and depth policies define how DDS buffers messages internally.
Most developers initially configure them once and never think about them again, but queueing behavior has enormous consequences on latency and system stability.
The most common configuration is keep_last, combined with a queue depth value.
For example:
1 | keep_last = 10 |
means DDS retains only the ten most recent samples.
This bounded behavior is usually desirable because robotics systems must remain predictable under load.
The alternative, keep_all, sounds attractive at first because it avoids losing historical data. But in practice, unbounded buffering often creates severe problems. Queues grow during overload conditions, latency increases progressively, stale data accumulates, and timing behavior becomes unpredictable.
This is particularly dangerous in robotics because systems often degrade gradually instead of failing immediately. Developers may not notice that subscribers are operating several seconds behind reality until robot behavior becomes unstable.
Large queues frequently hide performance problems instead of solving them.
In many robotics applications, it is actually healthier to drop old data aggressively than to preserve it indefinitely.
Deadline — Timing Guarantees Matter More Than People Think
The deadline QoS policy allows DDS to express expected publication timing.
For example, if a publisher specifies a deadline of 50 milliseconds, DDS expects new samples to arrive within that interval. If the publisher misses the deadline, middleware can trigger notifications or monitoring callbacks.
This becomes extremely useful for watchdog systems, fault detection, and control supervision.
Unfortunately, many ROS 2 systems ignore deadline policies entirely even though timing failures are often more dangerous than complete failures.
A robot that stops entirely is usually obvious.
A robot operating on stale sensor data with hidden latency accumulation is much harder to diagnose.
Deadline monitoring allows systems to detect degraded timing behavior before the robot enters unsafe or unstable states.
As ROS 2 deployments become larger and more distributed, these timing contracts become increasingly important.
Lifespan — Preventing Stale Data from Resurfacing
Lifespan defines how long messages remain valid before DDS automatically discards them.
This is another policy that initially feels unnecessary until delayed data suddenly causes unexpected behavior.
Imagine an obstacle detection topic transmitted over a congested wireless network. If old detections arrive several seconds late, they may no longer represent reality at all. A robot reacting to outdated obstacle information can easily make incorrect navigation decisions.
Lifespan policies prevent this situation by expiring messages after a predefined duration.
This ensures that delayed packets do not suddenly reappear long after they stopped being relevant.
For robotics systems dealing with perception, temporary detections, or rapidly changing environments, lifespan policies can dramatically improve behavioral consistency.
Liveliness — Detecting Dead Publishers
Liveliness allows DDS to monitor whether publishers are still alive even when no messages are currently being transmitted.
This becomes important when systems partially fail.
A process may freeze without crashing entirely. A network partition may isolate part of the graph. A publisher may silently disappear while subscribers continue waiting indefinitely.
DDS liveliness policies provide mechanisms to detect these situations automatically.
In distributed robotics systems, this becomes especially valuable for supervision layers, failover strategies, and safety monitoring.
As robots become increasingly modular and distributed across multiple machines, these failure-detection capabilities become much more important than they initially appear during local development.
The Hidden Reality — QoS Is a Compatibility Matrix
One of the most important operational lessons in ROS 2 is that QoS is not merely configuration.
It is compatibility negotiation.
Some publisher/subscriber combinations work perfectly.
Some partially work.
Some fail silently.
And many failures are not obvious from the ROS graph alone.
That is why debugging ROS 2 communication problems often requires understanding:
- DDS behavior,
- queueing,
- reliability negotiation,
- timing assumptions,
- network conditions,
- and startup synchronization.
Once systems scale beyond simple demos, QoS becomes a core architectural concern rather than a low-level implementation detail.
This is one of the major conceptual transitions between hobby ROS projects and production robotics systems.
rosbag2 and QoS — The Debugging Trap
QoS also affects recording and replay workflows through rosbag2.
And this is where debugging sessions can become particularly confusing.
Suppose a topic was originally recorded using best effort QoS. Later, during replay, subscribers expect reliable delivery.
Replay behavior may differ from the original runtime behavior even though the recorded messages themselves are identical.
This creates situations where a rosbag appears broken while the actual issue is simply QoS incompatibility between playback and subscribers.
The ROS 2 ecosystem includes QoS override mechanisms specifically because replay compatibility becomes critical in production robotics systems.
Useful references:
- https://docs.ros.org/en/humble/Concepts/Intermediate/About-Quality-of-Service-Settings.html
- https://docs.ros.org/en/humble/How-To-Guides/Overriding-QoS-Policies-For-Recording-And-Playback.html
- https://www.omg.org/dds/
If you already work heavily with observability, logging, and distributed ROS architectures, this topic connects naturally with the concepts discussed in ROS 2 architecture patterns that scale.
My Practical QoS Rules After Building Real Robots
After working on multiple ROS 2 systems, I increasingly rely on a few practical heuristics.
High-frequency sensor streams such as cameras, IMUs, and LiDAR data usually behave better with best effort communication because freshness matters more than historical completeness.
Critical coordination topics such as actuator commands, robot state, diagnostics, and mission events generally require reliable communication because consistency matters more than raw latency.
Static configuration data, calibration, maps, and TF static transforms almost always benefit from transient local durability because startup synchronization becomes dramatically simpler.
And perhaps most importantly: avoid oversized queues.
Large queues often create the illusion of resilience while actually introducing hidden latency and stale processing behavior. In robotics, bounded systems are usually healthier than systems attempting to preserve every packet forever.
Finally, before rewriting nodes or blaming DDS vendors, inspect QoS explicitly:
1 | ros2 topic info --verbose |
That single habit solves an extraordinary number of ROS 2 debugging sessions.
The Bigger Architectural Lesson
QoS is one of the clearest examples of what separates simple ROS demos from real robotics systems.
Once robots become distributed systems, communication behavior itself becomes part of the architecture.
Latency matters.
Freshness matters.
Bandwidth matters.
Startup ordering matters.
Partial failures matter.
Synchronization matters.
QoS exists because robotics systems operate in environments where those constraints are unavoidable.
And once you understand QoS properly, many “random ROS 2 bugs” stop looking random at all.
Most of them are simply communication contracts behaving exactly as configured.
Final Thoughts
Most ROS 2 communication issues are not magic.
They are usually:
- QoS mismatches,
- stale data problems,
- queueing issues,
- timing assumptions,
- or transport incompatibilities.
ROS 2 gives developers extremely powerful communication controls because robotics systems genuinely need them.
But those controls only become useful once you stop thinking of topics as simple pipes and start thinking of them as behavioral contracts between distributed software components.
QoS defines those contracts.
And understanding them is one of the biggest steps toward building ROS 2 systems that remain stable outside of demos and into real production robotics environments.